
- What is AI agent technical architecture in financial payment systems
- Where AI fits in the payment lifecycle
- Core reference architecture for AI in payment systems
- Model layer and inference services
- Real-time decisioning engine
- Execution and orchestration layer
- Real-time approval decision loop
- Control matrix: governance by design
- Implementation patterns: real-time, async, and batch
- Use cases: measurable business impact
- Agents as an optional pattern
- MLOps and model governance
- Where orchestration accelerates AI adoption
- Conclusion
- What is AI agent technical architecture in financial payment systems?
- What is the difference between rules, machine learning scoring, and agentic decisioning?
- How do payment systems maintain low latency for real-time fraud detection?
- Where do payment routing and retry logic fit in the AI stack?
- What data is required for a feature store in payment systems?
- How is success measured for AI in payment systems?
When companies talk about AI in payment systems, the conversation usually starts with models. Teams discuss fraud detection algorithms, anomaly detection, or predictive routing. However, in real-world implementations, models are rarely the hardest part.
The real challenge lies in how those models are embedded into a system that must operate under strict latency constraints, regulatory requirements, and direct revenue impact.
A payment authorization flow allows no margin for delay. If a decision arrives too late, the transaction fails. If it is too strict, it creates false declines and reduces conversion. If it cannot be explained, it becomes a compliance issue.
This is why implementing AI in payments is not a modeling task. It is a systems design problem.
Modern platforms rely on an event-driven architecture, where transaction data is captured in real time, enriched with context, evaluated by multiple models, and translated into actions through a centralized payment decisioning engine. All of this must happen within tens of milliseconds while remaining fully traceable.
This article provides a practical blueprint of how AI is implemented in payment systems, focusing on architecture, infrastructure, and deployment patterns rather than abstract theory.
What is AI agent technical architecture in financial payment systems
AI agent technical architecture in financial payment systems is a layered infrastructure that enables real-time decision-making by combining a streaming data pipeline, contextual enrichment, a feature store, model serving, a decision engine, orchestration, and governance controls.
Despite the term “agent,” this architecture is not about isolated AI components. It is about embedding intelligence into a distributed system that must remain fast, reliable, and compliant.
Where AI fits in the payment lifecycle
AI spans multiple stages of the payment lifecycle, each with different technical constraints.
Before a transaction, systems evaluate onboarding signals, merchant behavior, and KYB data. These processes are not latency-sensitive and typically run asynchronously.
During authorization, the system must decide whether to approve, decline, trigger 3D Secure (3DS), or select a routing strategy. This is where real-time fraud detection, fraud prevention, and payment routing operate under strict time limits.
After authorization, systems shift toward monitoring. This includes AML monitoring, chargeback analysis, and behavioral anomaly detection.
At the operational level, AI supports reporting, automation, and settlement reconciliation, ensuring consistency between transaction records and provider data.
Each of these stages uses the same architectural foundation but applies it under different performance requirements.
Core reference architecture for AI in payment systems
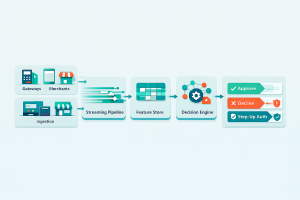
Modern implementations follow a layered architecture where each component performs a specific role in the decision pipeline.
The system begins with ingestion. Every transaction generates events that are processed through a streaming data pipeline, typically built on technologies such as Kafka or Kinesis. These systems ensure low-latency delivery of transaction data across services.
Once ingested, events are enriched with contextual data. Raw transactions are insufficient for decision-making. Systems compute features such as transaction velocity, user behavior patterns, and issuer response history. These features are stored in a feature store, ensuring consistency between training and real-time inference.
At this stage, infrastructure design becomes critical. One of the key questions is where models are deployed.
In perimeter-based architectures, models run inside internal infrastructure, usually in Kubernetes clusters within a private cloud. Inference services are deployed as containerized microservices, often written in Typescrypt and exposed via REST or gRPC APIs. This approach is preferred when PCI DSS and data residency requirements apply.
In cloud-based setups, models are hosted on platforms such as CloudFlare, AWS SageMaker or Google Vertex AI. This enables scalability and faster experimentation but introduces network latency and stricter requirements for secure data handling.
Most production systems adopt a hybrid approach. Real-time decisioning remains inside the perimeter, while training and non-critical workloads run in the cloud.
From a technology perspective, this architecture typically combines Kafka for streaming, Redis for low-latency feature access, and optimized inference runtimes such as ONNX Runtime or TensorFlow Serving.
Model layer and inference services
The model layer in payment systems is designed not only for accuracy but for speed and reliability.
Models are deployed as independent services rather than embedded in application code. This allows teams to update models without disrupting payment flows.
Two inference patterns are used.
Synchronous inference operates inside the authorization flow. These models must respond within milliseconds and support use cases such as real-time fraud detection and routing optimization. They are typically deployed close to the decision engine to minimize latency.
Asynchronous inference is used for AML monitoring and behavioral analysis. These models process transaction streams without blocking execution.
Inference services are exposed via low-latency APIs, often using gRPC. Models are preloaded into memory and executed in parallel to avoid delays.
Resilience is essential. If a model fails or exceeds latency limits, the system must fall back to rule-based logic. AI should improve decisions, but never block them.
Real-time decisioning engine
The payment decisioning engine aggregates model outputs, business rules, and compliance constraints into a final decision.
Technically, this engine is implemented as a low-latency microservice, often written in Go or Java. It evaluates inputs using rule engines or decision graphs, ensuring deterministic and explainable outcomes.
The result is a clear action: approve, decline, trigger authentication, or reroute the transaction.
Execution and orchestration layer
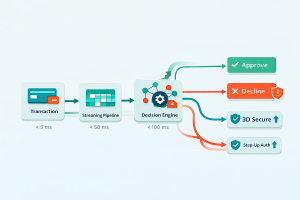
Once a decision is made, it must be executed through the payment infrastructure.
This is handled by a payment orchestration platform, which connects to multiple providers and implements execution logic such as payment routing, routing optimization, retry logic, and cascading payments.
From an infrastructure perspective, this layer operates as a real-time execution system with API integrations to acquirers and PSPs. It must support dynamic decisions without adding latency.
Real-time approval decision loop
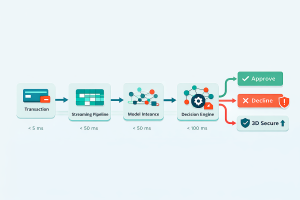
During authorization, the system operates as a tightly coordinated pipeline.
A transaction enters the gateway and is immediately processed through the streaming data pipeline. Features are retrieved from the feature store, models generate predictions, and the payment decisioning engine determines the final action.
The orchestration layer executes the decision.
Each component operates within a strict latency budget. Feature retrieval typically takes a few milliseconds, model inference tens of milliseconds, and decision execution must be nearly instantaneous. This ensures the entire pipeline remains within issuer limits.
Control matrix: governance by design
AI systems in payments must be governed at the architectural level.
Velocity controls detect abnormal transaction patterns at the feature layer. Policy rules such as allowlists and denylists are enforced in the decision engine. Authentication triggers like 3D Secure (3DS) are applied dynamically.
At the orchestration level, limits on retry logic prevent system overload. Fallback strategies ensure continuity if models fail.
All actions are logged, creating a complete audit trail.
This enables model governance, ensuring that decisions are explainable and compliant.
Implementation patterns: real-time, async, and batch
AI workloads are distributed across different execution modes.
- Real-time systems handle real-time fraud detection and routing decisions within the authorization flow.
- Asynchronous systems support AML monitoring and continuous analysis.
- Batch processing is used for settlement reconciliation, reporting, and model training.
Separating these workloads ensures stability and performance.
Use cases: measurable business impact
The architecture supports multiple use cases with clear business outcomes.
Fraud prevention analyzes transaction signals to reduce fraud while minimizing false declines.
Routing optimization selects the best provider to improve approval rate.
Decline recovery uses retry logic and cascading payments to recover failed transactions.
AML monitoring detects suspicious activity over time.
Settlement reconciliation ensures financial accuracy by identifying inconsistencies.
All these use cases rely on the same infrastructure foundation.
Agents as an optional pattern
Agentic payments introduce coordination between multiple evaluators, enabling parallel reasoning across fraud, identity, and routing.
However, agents do not replace core architecture. They rely on the same components: event-driven architecture, feature store, and model serving.
MLOps and model governance
Production systems require a structured MLOps lifecycle.
Models are trained, validated, deployed, and monitored. Shadow deployments and canary releases reduce risk.
Performance, latency, and drift are continuously tracked. If issues arise, rollback mechanisms restore previous versions.
Model governance ensures transparency through explainability and a full audit trail.
Where orchestration accelerates AI adoption
A payment orchestration platform connects AI decisions to execution.
It enables flexible payment routing, supports routing optimization, and executes retry logic and cascading payments.
Akurateco provides this orchestration layer along with analytics to measure improvements in approval rate and recovery.
Conclusion
AI in payment systems is not about adding models. It is about building infrastructure that can support intelligent decisions in real time.
Success depends on architectural choices: where models run, how latency is controlled, how decisions are governed, and how execution is handled.
Organizations that treat AI as infrastructure achieve measurable gains in fraud prevention, approval rate, and operational efficiency.
FAQ
What is AI agent technical architecture in financial payment systems?
The term ai agent technical architecture in financial payment systems describes the layered system infrastructure used to deploy intelligent decisioning across payment platforms. This architecture integrates streaming data ingestion, contextual feature computation, machine learning models, and decision orchestration.
Rather than focusing solely on AI agents, the architecture emphasizes reliable data pipelines, low-latency inference services, and transparent governance controls.
These components ensure that automated decisions remain explainable, traceable, and compliant with financial regulations.
What is the difference between rules, machine learning scoring, and agentic decisioning?
Rules are deterministic policies created by payment operators. They enforce simple constraints such as blocking high-risk countries or triggering authentication challenges.
Machine learning scoring introduces probabilistic predictions based on historical transaction patterns. These predictions estimate the likelihood of fraud or approval success.
Agentic decisioning refers to systems where AI agents coordinate multiple evaluations simultaneously. However, these agents still rely on the same underlying infrastructure of models, rules, and orchestration.
How do payment systems maintain low latency for real-time fraud detection?
Low latency is achieved through optimized event-driven architecture and real-time feature retrieval.
Streaming pipelines allow payment systems to process transaction events immediately as they occur. Feature stores maintain precomputed behavioral signals that models can access instantly.
Combined with efficient model serving infrastructure, these techniques enable fraud scoring to complete within milliseconds.
Where do payment routing and retry logic fit in the AI stack?
Routing and retry mechanisms operate at the orchestration layer of the payment architecture.
After the payment decisioning engine evaluates model predictions and policy rules, the orchestration platform executes the chosen strategy.
AI models help determine which provider route is most likely to succeed and whether retry attempts should occur. The orchestration platform then implements those decisions using payment routing, retry logic, and cascading payments.
What data is required for a feature store in payment systems?
Feature stores collect both transactional and contextual signals.
Typical features include transaction velocity, device fingerprint reputation, geographic patterns, historical decline rates, and issuer approval behavior.
These signals must be updated frequently to reflect current behavior. Feature stores also maintain strict versioning to ensure consistency between model training and real-time inference pipelines.
How is success measured for AI in payment systems?
Success metrics extend beyond simple model accuracy.
Payment teams typically measure improvements in approval rate, reductions in false declines, recovery rates from retry strategies, and operational efficiency gains.
These metrics directly reflect the business value generated by intelligent payment decisioning systems.



